
Webサイトのリニューアルや移行を担当していると、旧サイトの構造を事前に把握したい場面があります。
どのようなURL体系になっているのか。HTML、CSS、JS、画像がどこに置かれているのか。テンプレートや共通パーツはどう分かれているのか。CMSを使っているのか、静的HTMLが積み上がっているのか。
そうした調査のために、Webサイトを再帰的にクロールしたり、必要に応じてローカルへダウンロードしたりすることがあります。この記事では、主に Wget を使ってサイトを丸ごと取得する方法を整理します。
ただし、これはあくまで調査や移行準備のための方法です。自分が管理していないサイトに対して無断で大量アクセスを発生させるのは避けるべきです。対象サイトの管理者に確認し、アクセスの少ない時間帯に実行し、必要に応じて待機時間を入れるなど、相手側のサーバーに負荷をかけない配慮が必要です。
まずはクロールで構造を見る
サイト全体の構造を把握するだけなら、必ずしもファイルを丸ごとダウンロードする必要はありません。
SEO系のクローラーを使えば、URL一覧、ステータスコード、タイトル、見出し、メタ情報、内部リンク、画像の有無などを確認できます。サイト規模の把握やリニューアル前の棚卸しであれば、まずはこちらの方が効率的です。
代表的なツールとしては、Screaming Frog SEO Spider があります。無料版ではクロールできるURL数に制限がありますが、小規模なサイトや事前調査には十分使えます。Google Analytics、Search Console、PageSpeed Insights などと連携して分析できる点も便利です。
一方、実際のHTMLやCSSをローカルで確認したい場合、あるいは旧サイトの静的ファイル構成を確認したい場合は、ダウンロード系のツールが役立ちます。
GUIツールでダウンロードする
コマンド操作に慣れていない場合は、GUIツールを使う方法もあります。
macOSであれば SiteSucker のようなアプリがあります。URLを指定して、リンクをたどりながらHTMLや画像、CSSなどをローカルへ保存できます。設定画面で取得範囲やファイル種別を調整できるので、軽く試すには扱いやすいと思います。
Windows環境では、以前から Website Explorer のようなツールも使われてきました。ただ、更新状況や対象サイトとの相性もあるため、現在使うなら事前に動作確認した方がよいです。
GUIツールは手軽ですが、細かい条件を指定したり、繰り返し同じ条件で実行したりする場合は、コマンドの方が扱いやすいこともあります。
Wgetを使う
Wget は、HTTPやHTTPSなどを使ってファイルを取得できるコマンドラインツールです。再帰的なダウンロードや、リンク変換、ページ表示に必要な画像・CSSの取得などに対応しています。
macOSであれば、Homebrewを使ってインストールできます。
brew install wgetシンプルにサイトをミラーリングする場合は、以下のように実行します。
wget -m -p -E -k -np https://example.com/実際に自分のサイトや管理対象サイトで試す場合は、https://example.com/ の部分を対象URLに置き換えます。
よく使うオプション
上記のコマンドで使っている主なオプションは以下です。
| オプション | 説明 |
|---|---|
-m, --mirror | ミラーリング用の指定。再帰取得やタイムスタンプ確認などをまとめて有効にする |
-p, --page-requisites | ページ表示に必要な画像、CSS、JSなども取得する |
-E, --adjust-extension | HTMLやCSSなどをローカルで扱いやすい拡張子に調整する |
-k, --convert-links | ローカルで閲覧できるよう、取得済みファイルへのリンクを書き換える |
-np, --no-parent | 指定した階層より上のディレクトリを取得しない |
もう少し実務寄りに使うなら、次のように待機時間やUser-Agentも指定しておくと扱いやすいです。
wget -m -p -E -k -np -nH -N -w 1 \
-U="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36" \
https://example.com/追加でよく使うオプションも整理しておきます。
| オプション | 説明 |
|---|---|
-nH, --no-host-directories | ホスト名のディレクトリを作らない |
-N, --timestamping | ローカルより新しいファイルだけ取得する |
-w, --wait=SECONDS | ダウンロードごとに指定秒数待つ |
-U, --user-agent=AGENT | User-Agentを指定する |
-q, --quiet | 実行中の出力を抑える |
-i, --input-file=FILE | ファイルに記載したURLをまとめて取得する |
-nc, --no-clobber | 既存ファイルを上書きしない。ただし、リンク変換と併用しづらい場合がある |
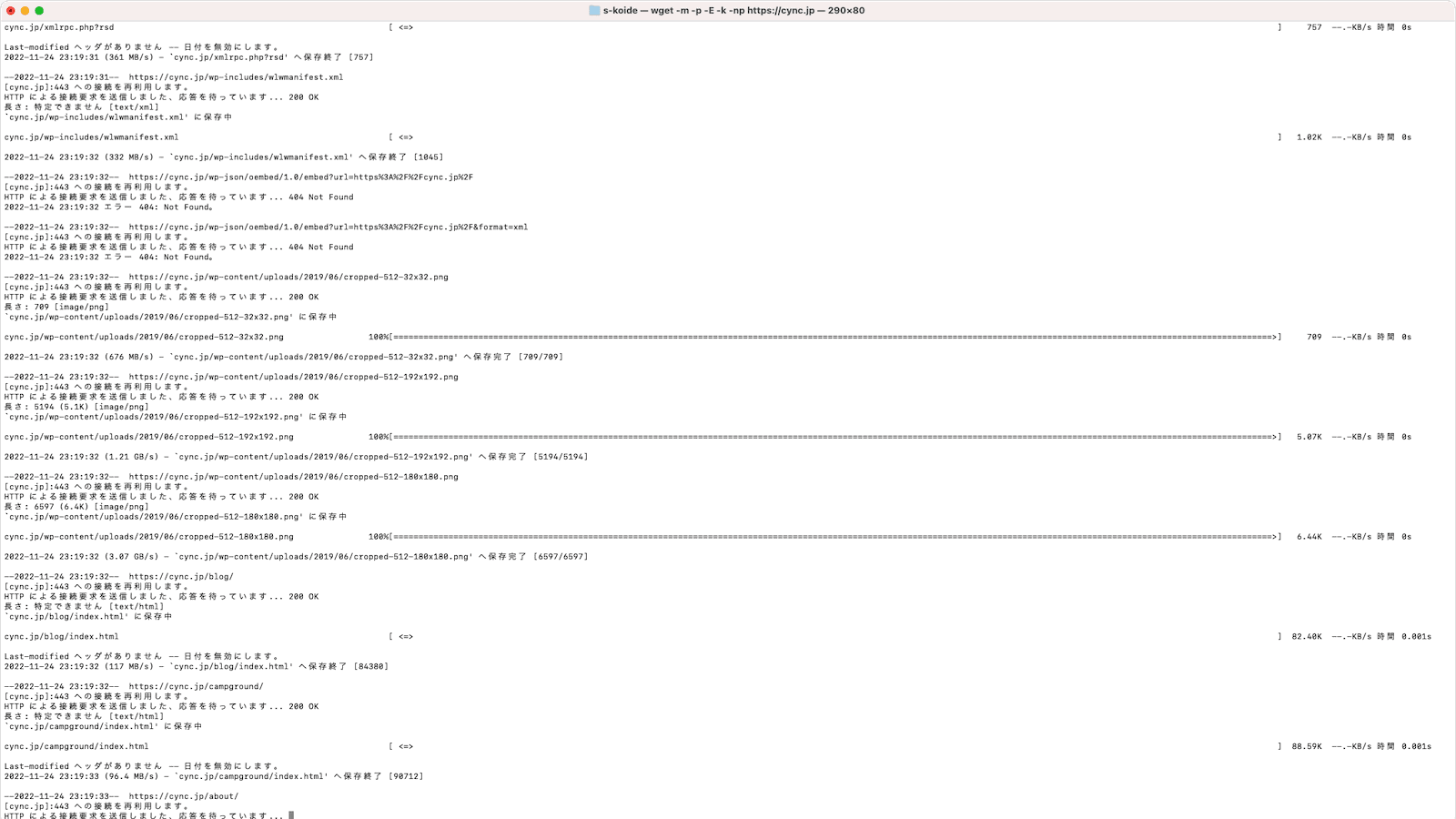
ダウンロード後に見るところ
ダウンロードが終わったら、VS Codeなどで保存先のディレクトリを開きます。
見るべきポイントは、だいたい以下です。
- URLやディレクトリがどの単位で分かれているか
- HTML、CSS、JS、画像ファイルの格納場所
- 共通ヘッダー、フッター、ナビゲーションの作られ方
- テンプレート化されていそうな箇所
- 使われているライブラリやUIフレームワーク
- 画像やPDFなど、移行時に拾い漏れやすいファイル
- リダイレクト設計に必要な旧URLの一覧
-k を付けてリンクを変換しておけば、取得したHTMLをブラウザで開いてある程度確認できます。ただし、完全に本番と同じ状態で再現できるとは限りません。
うまく取得できないケース
Wgetで丸ごと取得できるのは、基本的にはHTMLとしてリンクをたどれるサイトです。
SPAやJavaScriptで画面を生成しているサイト、ログインが必要なサイト、フォーム操作が必要なサイト、画像やAPIの取得に制限があるサイトでは、期待通りに保存できないことがあります。
また、robots.txt やサーバー側の制限、WAF、CDNの設定によって、クロールや大量アクセスがブロックされることもあります。管理対象サイトであれば、必要に応じてサーバーログを見ながら実行した方が安全です。
単にURL一覧を作りたいだけなら、SEOクローラーを使う。実際のHTMLや静的アセットを手元で見たいなら、WgetやGUIツールを使う。目的に応じて使い分けるのがよいと思います。
まとめ
Webサイトを丸ごとダウンロードする方法は、リニューアル前の調査や移行準備では今でも役に立ちます。
ただし、目的は「コピーすること」ではなく、構造を把握することです。旧URLを洗い出し、ファイル構成を見て、設計や実装のクセを掴む。そのための手段として、WgetやSEOクローラーを使うのが現実的です。
対象サイトへの負荷や権利関係には気を付けつつ、必要な範囲で丁寧に使いたいところです。